Home > Information > News
#News ·2025-01-07


This article is reprinted with the authorization of AIGC Studio public account, please contact the source for reprinting.
InstructMove is an instruction-based image editing model that uses instructions generated by multimodal LLM to train pairs of frames in video. The model excels at non-rigid editing, such as adjusting the subject's posture, expression, and changing the point of view, while maintaining consistency. In addition, the method supports accurate local editing by integrating masks, human postures, and other control mechanisms.


Command-based image manipulation by observing how things move
This paper introduces a novel data set construction process that extracts frame pairs from video and generates editing instructions using a multimodal Large language model (MLLM) to train an instruction-based image processing model. Video frames essentially retain the identity of the subject and scene, ensuring consistency in content preservation during editing. In addition, video data captures a variety of natural dynamics (such as non-rigid subject movements and complex camera movements) that are otherwise difficult to model, making it an ideal source for building scalable datasets. Using this approach, we created a new dataset to train InstructMove, a model capable of complex instruction-based operations that are difficult to implement by synthesizing the generated dataset. Our models show state-of-the-art performance for tasks such as adjusting subject poses, rearranging elements, and changing camera perspectives.
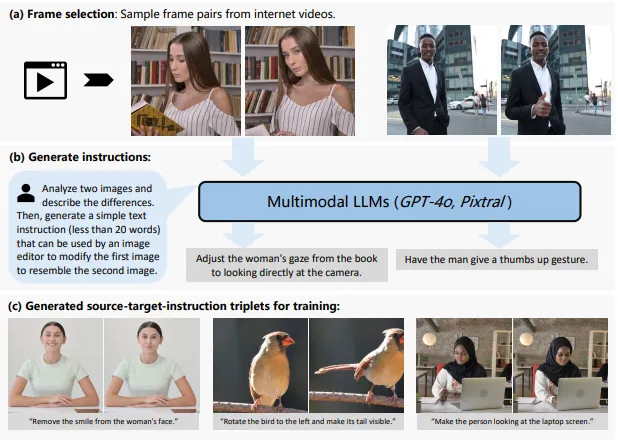
Data build pipeline:
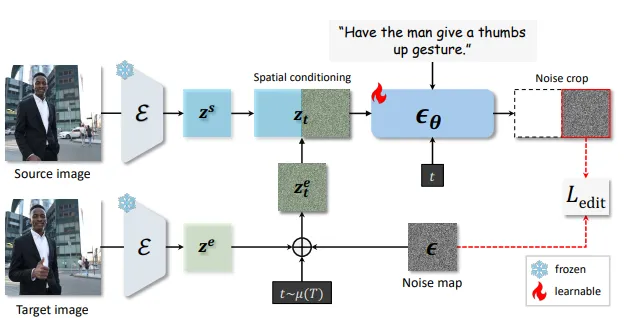
Overview of model architecture for instruction based image editing. The source and target images are first encoded as potential representations zs and ze using a pre-trained encoder. Then the target potential ze is converted into noise potential Z ET by a forward diffusion process. The source image potential and noise target potential are connected along the width dimension to form the model input, which is input into the de-noised U-Net ϵθ to predict the noise map. The right half of the output (corresponding to the noise target input) is cropped and compared to the original noise map.

 Qualitative comparison with state-of-the-art image editing methods, including description-based and instruction-based methods. Existing methods struggle to handle complex edits, such as non-rigid transformations (such as changes in posture and expression), object repositioning, or viewpoint adjustments. They often either fail to follow editorial instructions or produce inconsistent images, such as identity shifts. In contrast, the paper's approach, trained on real video frames with natural transformations, successfully processed these edits while maintaining consistency with the original input image.
Qualitative comparison with state-of-the-art image editing methods, including description-based and instruction-based methods. Existing methods struggle to handle complex edits, such as non-rigid transformations (such as changes in posture and expression), object repositioning, or viewpoint adjustments. They often either fail to follow editorial instructions or produce inconsistent images, such as identity shifts. In contrast, the paper's approach, trained on real video frames with natural transformations, successfully processed these edits while maintaining consistency with the original input image.
 Qualitative results of the method and additional control are obtained.
Qualitative results of the method and additional control are obtained.
This paper presents a method to sample video frames and use MLLM to generate editing instructions to train an instruction-based image processing model. Unlike existing datasets that rely on synthetically generated target images, this approach leverages supervised signals from video and MLLM to support complex edits, such as non-rigid transformations and viewpoint changes, while maintaining content consistency. Future work could focus on improving filtering techniques, whether by improving MLLM or incorporating human-computer interaction processes, as well as integrating video data with other datasets to further enhance image editing capabilities.

2025-02-17

2025-02-14

2025-02-13


抖音二维码

微信公众号

QQ群:

小红书二维码
friend link


400-000-0000
立即获取方案或咨询
top







