Home > Information > News
#News ·2025-01-06


The writers are from Zhejiang University, University of Science and Technology of China, Institute of Automation, Chinese Academy of Sciences, and Nanqi Xiance List of authors: Deng Yue, Yu Yan, Ma Weiyu, Wang Zirui, Zhu Wenhui, Zhao Jian and Zhang Yin. First author Deng Yue is a doctoral student in the Department of Computer Science at Zhejiang University. Corresponding authors are Dr. Jian Zhao, Xiance Nanqi, and Zhang Yin, Professor of Computer Science at Zhejiang University.
In the field of artificial intelligence, challenging simulation environments are critical to advancing the field of multi-agent reinforcement learning (MARL). In the cooperative multi-agent reinforcement learning environment, most algorithms use the StarCraft Multi-Agent Challenge (SMAC) as an experimental environment to verify the convergence and sample utilization of the algorithms. However, with the continuous progress of MARL algorithms, many algorithms show near-optimal performance in SMAC environment, which makes the evaluation of the real effectiveness of algorithms more complicated. Although the SMACv2 environment uses probabilistic generation for task initialization to weaken open-loop control, both environments use the default, single, deterministic script as the counterpart script. This makes it easier for the strategy model learned by the agent to overfit to a certain opponent strategy, or to use the vulnerability of the opponent strategy to fit to the cheat method.

Figure 1: The default script for SMACv1 (left) and SMACv2 (right). They are: "Manipulate all Player 2's characters to attack Team1's position" and "Manipulate each player 2's characters to attack Player 1's nearest character".
To illustrate the impact of the default script, the following three video replays are from the default opponent policy of SMACv1 and the appropriate opponent policy of SMACv2.
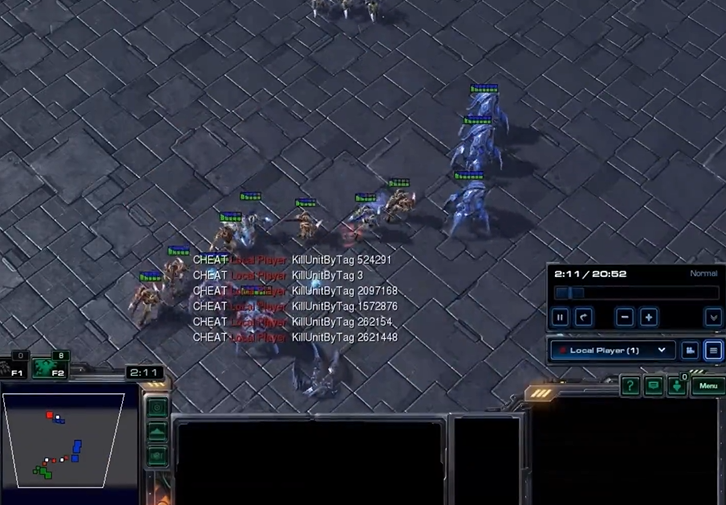
In the SMACv1 environment, the opponent zealot is stuck in the Team1 position by the hate scope and script, leaving the other characters to fight.
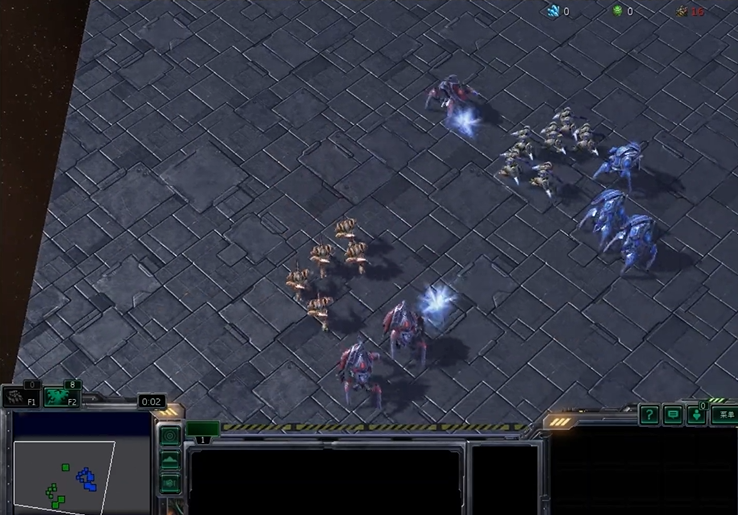
In the SMACv2 environment, because the default opponent strategy is to attack the nearest character, the opponent zealot is attracted to stalker and disengaged from the other character's battle.
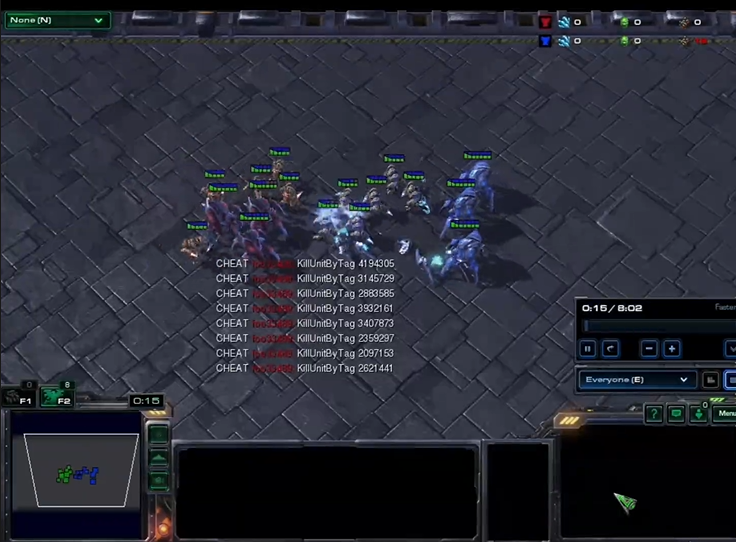
In SMAC-HARD, enriching the opponent strategy gives the agent a more normal and greater challenge.
Recently, Zhejiang University and Nanqi Xiance jointly launched the SMAC-HARD environment based on the SMAC simulation environment. The environment supports editable opponent strategy, randomized opponent strategy and MARL self-game interface, so that the agent training process can adapt to different opponent behavior and improve the stability of the model. In addition, the agent can also evaluate the policy coverage and migration ability of the MARL algorithm by completing a black box test in the SMAC-HARD environment, that is, the agent only deduces against the default opponent strategy or self-game model during training, but interacts with the script provided by the environment during the test.
The team evaluated widely used advanced algorithms on SMAC-HARD, showing that current MARL algorithms achieve more conservative behavioral values in the face of mixed editable adversary strategies, resulting in policy networks converging to suboptimal solutions. In addition, black-box strategy testing also demonstrates the difficulty of transferring learned strategies to unknown opponents. By introducing the SMAC-HARD environment, the team hopes to raise new challenges for subsequent MARL algorithm evaluation and promote the development of self-game methods in the multi-agent system community.

In terms of source code, the Python-based pysc2 code package is an abstraction of sc2_protocol in the StarCraft II binary game file. Through pysc2's abstraction of the sc2_protocolAPI, players can control the progress of the game. The SMAC framework further encapsulates the API provided by pysc2 by converting the original observation data of pysc2 into standardized, structured and vectorized observation and state representation. As a result, the StarCraft II environment itself supports both standardized actions from SMAC and actions generated by pysc2 scripts, which provides support for adversary editable scripts. As shown in Figure 2, SMAC-Hard modifies the map in SMAC (SC2Map) to enable multi-player mode and disables the default attack strategy to prevent action interference in the default script strategy. In addition to the modifications to the map, the original SMAC's starcraft.py file was also modified to accommodate two players to enter the game, retrieve the original observations of both players, and process the actions of both players simultaneously. To mitigate the effect of the order of action execution, the environment parallelizes the action progression of two players.

Figure 2: Schematics of the relationship between SMAC-Hard environment, opponent strategy script, self-game interface encapsulation, and original SMAC, PySC2, StarCraftII.
In addition to providing decision tree modeling for opponents, when there are multiple opponent strategies, the environment also introduces a random strategy selection function set by predefined probabilities to improve the richness of opponent strategies. These probabilities are expressed as a list of floating point values and are set by default to equal probability for all policies. In addition, in order to further expand the strategy richness of the opponent, the environment also provides a similar symmetric interface to the opponent based on the encapsulation of the agent's observation, state, and available behavior to promote the development of MARL self-game model. The user can control the use of autogame mode or decision tree mode by the "mode" parameter, and the mode defaults to decision tree mode. Based on this premise, the user can change the SMAC in the import to smac_hard, and the experimental environment can be seamlessly transferred from SMAC to SMAC-hard.

Figure 3: The process of generating a two-party policy script from a large model. In a symmetric environment, both strategies are adopted as optional strategies.
Although decision trees show higher stability and can provide stronger interpretability in the face of different opponent strategies. Referring to the recent work LLM-SMAC, the generation of adversary policies can be done through large models of code to aid policy scripting. As shown in Figure 3, role information, map information, and task description are combined into environmental prompts, and a large planning model is used to plan the strategy architecture for both parties. Both sides use the code large model to implement their own policy architecture, and use the generated code to evaluate in SMAC-HARD. Using the large model as a critic to analyze the evaluation results and code for several rounds, and then provide optimization suggestions for planning the large model and code large model.

After testing five classical algorithms, the SMAC-HARD environment presents a greater challenge to the basic MARL algorithm. In contrast to the original SMAC task, where almost all algorithms achieved a near-100% win rate in 10 million time steps, SMAC-Hard introduced a higher difficulty and convergence challenge. For example, as shown in Figure 4 and Table 1, the 2m_vs_1z task is relatively easy in the raw SMAC environment, but becomes extremely difficult in SMAC-hard. In SMAC-HARD, Zealot always targeted one Marine, which required one Marine to move to avoid damage, while the other focused on attack. This makes it necessary for each agent to perform the correct behavior continuously, which poses a huge challenge for MARL algorithms.

Figure 4:10M step test curve of classical algorithm in SMAC-HARD environment.

Table 1: Test results of 10M steps of the classical algorithm in the SMAC-HARD environment.
To test the policy coverage and migration ability of MARL algorithm, SMAC-HARD provides a black box test mode. The MARL algorithm is trained for the default opponent strategy for 10M steps, and then tested for the mixed opponent strategy. The test results are shown in Table 2. It is worth noting that, in contrast to the black-box assessment, the win rate increases with the difficulty of the task, creating an opposite trend for 3s_vs_3z, 3s_vs_4z, and 3s_vs_5z tasks. When Stalker is facing a Zealot, the Stalker character can "kite" the Zealot by moving at a higher speed. The environment of 3s_vs_5z is more challenging, and the agent must adopt the optimal coping strategy of strict "kite" mechanism to win. Agents that learn the best coping strategies are more likely to succeed against the adversary script in the black box test.

Table 2: Test results of the classic algorithm in the black box mode of SMAC-Hard after 10M steps training in SMAC environment.
In addition, the reward settlement error in the original SMAC environment for the opponent's health and shield recovery makes it easy for the agent to fall into the optimal solution to maximize the reward, but the suboptimal solution of the win rate settlement. As an experimental environment, SMAC has evaluated several algorithms, so although the reward settlement error of SMAC is found, SMAC is not convenient to correct, so the experimental results are not comparable. With the introduction of a new assessment environment, SMAC-Hard fixed the reward settlement bug from SMAC.

Figure 5: SMAC Environment authors' response to the issue of reward settlement.
To sum up, this paper introduces an SMAC-HARD environment that supports opponent script editing, predefined probability mixed opponent strategy, and self-game interface alignment to address the lack of diversity of strategy space in the single default opponent strategy used in SMAC. The results show that even the popular MARL algorithm, which performs almost perfectly in the traditional SMAC environment, is difficult to maintain a high win rate in the SMAC-hard environment. In addition, the environment performs a black-box evaluation of models trained using MARL algorithms, highlighting the limited transferability of MARL strategies in the face of a single, vulnerable adversary strategy. Finally, the environment aligns the training interface of the counterparty with that of the agent, providing a platform for potential MARL self-game field research. It is hoped that SMAC-HARD can contribute to MARL community research as an editable and challenging environment.

2025-02-17

2025-02-14

2025-02-13


抖音二维码

微信公众号

QQ群:

小红书二维码
friend link


400-000-0000
立即获取方案或咨询
top







