Home > Information > News
#News ·2025-01-03



Transformer architecture has become the cornerstone of today's large models, no matter in the field of NLP or CV, the current SOTA models are basically based on Transformer architecture, such as various well-known large models in NLP, or Vit and other models in CV
The paper title of this presentation is: Tokenformer: Rethinking Transformer Scaling with Tokenized Model Parameters, "Tokenformer: Rethinking Transformer scaling with Tokenized model parameters," As the name suggests, this paper proposes the Tokenformer architecture, which has the advantage of incremental learning ability: When increasing the size of the model, there is no need to retrain the model from scratch, which greatly reduces the cost. The code for this article is open source.
First, we compare the traditional Transformer architecture with the Tokenformer architecture proposed in this paper from the perspective of top-level design, as shown in the following figure:

The self-attention mechanism is at the heart of Transformer and consists of the following steps:






As shown above, a Transformer layer consists of two main parts:
Traditional Transformer relies on a fixed number of linear projections when dealing with the interaction between tokens and parameters, which limits the scalability of the model. This statement itself is difficult to understand, so the shortcomings of the architecture will be discussed in detail next.
Scalability refers to the ability of a model to effectively increase its scale (e.g. number of parameters, computing power, etc.) when more powerful performance is needed without performance degradation or excessive computing costs.
In short, a well-scaled model can be scaled flexibly and efficiently while maintaining or improving performance.

To address the lack of model extensibility caused by fixed model dimensions, TokenFormer proposes an innovative approach that enables more efficient and flexible model scaling by treating model parameters as tokens and leveraging attention mechanisms to handle the interactions between tokens and parameters.

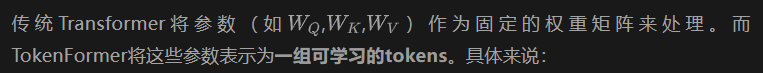
Parameters Tokens: The Q, K and V projection layers of the original transformer model are no longer fixed matrices, but are converted into a set of vectors (tokens), such as:

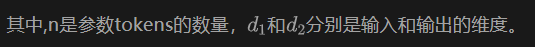
The Pattention layer, a core innovation of TokenFormer, deals with the interaction between tokens and parameters through an attention mechanism. Thus replacing the original Q,K,V, the specific process is as follows:







For ease of reading, throw the graph here again:

Like the traditional transformer architecture, it generally includes two layers: a multi-head self-attention layer and a feedforward network layer.




It can also be seen here that compared to Transformer, Tokenformer is transforming all projection layers from a fixed fully connected network to a Pattention layer.

The left side of the formula below represents the self-attention mechanism of traditional Transformer, and the right side represents the self-attention mechanism of tokenformer:

As can be clearly seen from the above figure, compared with transformer, this paper only replaces the projection layer and the connection layer with a new layer.
As mentioned before, compared with transformer, tokenformer is mainly to solve the problem of scalability, so if we want to increase the number of parameters or increase the input dimension, how does tokenformer carry out incremental learning?



In this way, the number of parameters in the model can be expanded as needed.
Initialization strategy: Newly added parameters tokens are initialized to zero, similar to LoRA technology (Low-Rank Adaptation), ensuring that the model can quickly adapt to new parameter extensions while maintaining the original knowledge.

Compared to a Transformer trained from zero weight, as shown in the figure above, the Y-axis represents model performance and the X-axis represents training costs. The blue lines represent Transformer models trained from scratch using 300 billion tokens, and different circle sizes represent different model sizes.
Other lines represent the Tokenformer model, and different colors represent different Token numbers. For example, the red line starts with 124 million parameters, expands to 1.4 billion parameters, and its training set is 30B tokens sampled from 300B tokens. The performance of the final model is comparable to a Transformer of the same size, but the training cost is greatly reduced.
The yellow line shows that the incremental version trained with 60B tokens already performs better than Transformer at a lower training cost.

2025-02-17

2025-02-14

2025-02-13


抖音二维码

微信公众号

QQ群:

小红书二维码
friend link


400-000-0000
立即获取方案或咨询
top







