Home > Information > News
#News ·2025-01-07


Open world 3D Scene understanding aims to identify and distinguish open world objects and categories from 3D data such as point clouds without the need for manual annotation. This is crucial for real-world applications such as autonomous driving and virtual reality. Traditional closed set recognition methods that rely on manual annotation cannot meet the challenge of open world recognition, especially 3D semantic annotation, which is very costly in manpower and material resources. A large amount of Internet text-visual pair data makes 2D visual language model show outstanding 2D open set world understanding ability. Similarly, in order to understand the 3D open world, the current SOTA method achieves 3D open world understanding by constructing point cloud-text-to-data, and then using CLIP's comparative learning method. This approach requires not only a cumbersome point cloud-text to data production process, but also a large number of point cloud text alignment data. In the real Internet world, a large amount of 3D point cloud data is difficult to obtain and is limited, thus limiting the production of a large number of point cloud-text data, which in turn limits the performance ceiling of the method.
A closer look reveals that although 3D point cloud data is limited, they often appear in pairs with images. This led us to think carefully about whether the success of 2D open-world understanding methods could be used to transfer the power of 2D open-world understanding to 3D open-world understanding with limited data, using images as a medium. Therefore, we design a unified multimodal learning framework of point cloud-image-text, and transfer the image-text alignment relationship to point cloud-text in the case of limited data to get a 3D open set scene understanding model. This framework does not need to produce point cloud-text pairs, but only obtains regional pixel-text pairs through 2D basic models, and can obtain 3D open set scene understanding models through multi-modal unified training. At the same time, the semantic information of the point cloud can be obtained without relying on the image during inference. Multiple experiments on the widely used nuScenes, Waymo, and SeamanticKITTI datasets validate the effectiveness of multimodal frameworks for 3D open-set tasks.

This paper proposes a multimodal open set framework UniPLV, which unifies point cloud, image and text into a single paradigm to realize open world 3D scene understanding. UniPLV uses image modes as a bridge to embed 3D point clouds with pre-aligned images and text into a shared feature space, eliminating the need to make aligned point clouds and text data. To achieve multi-modal alignment, we propose two key strategies: (i) logical and feature distillation modules for image and point cloud branches; (ii) A visual point cloud matching module for explicitly correcting misalignments caused by point cloud to pixel projection. In addition, to further enhance the performance of our unified framework, we employ four task-specific loss functions and a two-stage training strategy. A large number of experiments show that our method outperforms the most advanced method on Base-Annotated and Annotation-Free tasks by 15.6% and 14.8% on average.
3D semantic segmentation. 3D semantic segmentation technology can be divided into three categories according to the modeling method of point cloud: view-based, point-based and voxel-based. view-based transforms 3D point clouds into distance views or bird 's-eye views, extracting 2D features but losing 3D geometric features. point-based uses 3D points directly as model inputs and designs algorithms to aggregate contextual information. Voxel-based divides the point cloud space into multi-voxel grids and uses sparse convolution techniques to process these Voxel features to improve efficiency. In this paper, MinkUNet, SparseUnet32 and PTv3 are used as backbone networks to verify the scalability and generalization ability of the proposed framework.
Open vocabulary 2D scene understanding. 2D Scene understanding techniques With the development of large-scale visual language models, significant progress has been made in the ability to understand 2D open-world scenes. There are two main directions: the Clip-based method and the Grounding method. Clip-based methods typically use CLIP text features instead of linear projection features and use contrast learning for feature alignment, such as GLEE, the DetCLIP family, RegionCLIP, and OWL-ViT. The input of a Grounding task is a picture and its corresponding description. The positions of the object boxes are output in the image with different descriptions. Given the success of 2D open world understanding, we chose GLEE and Grounding DINO as our 2D open set region tag generation algorithms.
Open vocabulary 3D scene understanding. Open vocabulary 3D scene understanding aims to identify unlabeled objects. The early methods mainly achieve the understanding of open scenarios through the method of feature differentiation or generation. With the success of visual language models such as CLIP, there has been a lot of work to transfer visual language knowledge to 3D scene understanding. Clip2Scene uses a frozen CLIP to obtain semantic labels for the images, which are then projected to guide the semantic segmentation of the point cloud. OpenMask3D uses a 3D instance split network to create 3D masks and projects them to obtain 2D masks. These 2D masks are fed into the CLIP to extract visual features and match them with text features, ultimately obtaining 3D semantics. Since CLIP is trained based on the alignment of complete images and text, its ability to understand specific areas is limited. OpenScene achieves point-cloud alignment with text by projecting the prediction from a frozen 2D visual model and distilling between the image and the point cloud features. However, OpenScene requires resource-intensive feature extraction and fusion, and the image backbone is fixed during training, making it difficult to scale to more advanced 3D networks and 3D scenes. RegionPLC and PLA realize 3D understanding of open scenes by building a large number of point cloud text pairs to train point cloud alignment with text. This paper proposes a unified multimodal framework for open scene 3D understanding, which is lightweight and scalable, and does not require the generation of additional point cloud text pairs.
UniPLV is able to recognize new categories without manual labeling while maintaining performance over base categories that have been labeled. Unlike previous approaches to open vocabulary understanding by building 3D point-text pairs, our work utilizes a 2D base model to build semantic labels for image regions, migrating open set capabilities from 2D to 3D without the need for additional 3D and text pairing data. Using the mapping relationship between 2D and 3D Spaces and pre-aligned images and text, we design a multimodal unified training framework that uses images as Bridges to embed point cloud features into the shared feature space of images and text. We introduce the main components of the proposed framework, data flow transformation, two knowledge distillation modules and a visual point matching module. We introduce a multi-modal and multi-tasking training strategy to ensure stable and efficient training of point clouds and image branches. In the inference phase, the framework only needs the point cloud and category description as inputs to calculate the feature similarity, and selects the most similar category as the semantic prediction for each point.

We use 2D visual-language model to extract image instance and pixel semantics. Specifically, given a set of text lists of images and categories, output a bounding box, instance mask, and semantic category for each image. We used GLEE for instance mask and bounding box generation, and the model has been trained on large datasets and has excelled in accuracy and generalization. In addition, we combined Grounding DINO and SAM2 to generate another set of instance tags. The bounding boxes are generated by Grounding DINO, and then each box is further split using SAM2 to produce the instance mask. At this point, we obtain region-pixel-text pairs, as well as point clouds aligned with image space-time, for training the proposed multimodal 3D scene understanding network. In the experimental results of this paper, the 2D semantic tags are from GLEE, and the relevant Grounding DINO and SAM2 experiments can be found in the supplementary materials.
The proposed UniPLV consists of a frozen text encoder, image codec-decoder, and a point cloud segmentation network, as shown in Figure 2. We enter all category names into the text encoder as text prompt, and apply global average pooling on the sequence dimension to obtain text features. To support open world understanding, we replace the classifier for image decoders and 3D segmentation heads with a measure of similarity between perceptual features and text features:
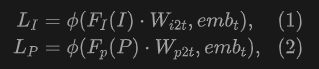
UniPLV can leverage the constructed regional image-text pair to fine-tune segmentation and detection of images and provide point cloud segmentation results corresponding to a given category. The final optimization goal of the framework is to embed point cloud features and image-text features into a unified feature space through multi-modal joint training, and realize the alignment of point cloud and text in the understanding of open world 3D scenes. For the image and text branches, we load GLEE's Phase 2 model as a pre-training weight to enhance text and image alignment. During the training process, we fine-tune the image model using data built from the two-dimensional base model, and during the iterative training process, the model performs feature clustering to identify and learn common properties of a given class. This mechanism helps to filter out the noise introduced by false detection, so as to effectively clean false labels.
In order to use image as a bridge to embed point cloud features and pre-aligned image-text pairs into a unified feature space, we introduce two distillation modules from image branch to point cloud branch: logical distillation and feature distillation.
Logical distillation. The semantic classification probability of image pixels is obtained by measuring the similarity between image features and all text features of a given class. Similarly, the semantic classification probability of point clouds is also obtained by calculating the similarity to text. We design a logical distillation to supervise the point cloud classification of a new class. The semantics of the new class are predicted and projected by the image branches. Cross-entropy loss and Dice loss are used to implement logical distillation:
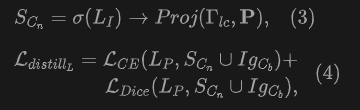
Characteristic distillation. The alignment between images and text has been pre-trained using large-scale data. In order to bridge the feature gap between point clouds and semantic text, we further use image features to distil the features of point clouds. We only distil 2D-3D pairing points that are both spatially mapped and semantically aligned. Feature distillation is carried out based on similarity calculations, using the cosine similarity function to measure feature similarity between point clouds and images in specific pairs:
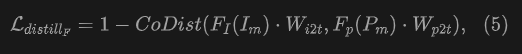
We introduced the Vision-point Cloud Matching (VPM) module to further learn fine-grained alignment between images and point clouds. This is a binary classification task that requires the model to predict whether a pair of pixels from a projection will match positively or negatively. VPM mainly consists of an attention encoder module and a binary classifier. Given the paired image feature and point cloud feature, the image feature is the query vector, while the point cloud feature is the key and value vector. Self-attention is applied to image features to obtain image attention features. The subsequent cross attention is carried out between the image and the point cloud features, and the cross features are output through the feedforward network to a binary classifier to obtain the matching probability:
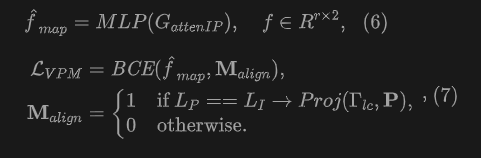
To achieve 3D open world scene understanding, we jointly train alignment between image pixels, 3D point clouds, and text. Our proposed UniPLV has four task-specific losses: image-text alignment, point cloud-text alignment, pixel-point cloud matching, and logical and feature distillation losses. The final total loss is calculated as follows by weighted combination of the above four losses:
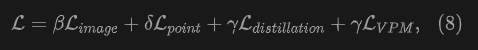
In order to achieve multi-modal stability training, we propose a two-stage multi-task training strategy for training the multi-modal framework UniPLV.
Stage 1: Independent image branch training. In the initial stage of training, we independently trained the image branches to maintain half of the total iteration steps to ensure the network gradient synchronization of the two modes, and implemented gradient clipping during the image branch training to prevent gradient explosion and ensure the training stability.
Stage 2: Unified multimodal training. The second stage involves the joint training of image and point cloud branches with different loss weights to effectively balance their loss values. Throughout the training process, we use the AdamW optimizer, chosen for its adaptive learning ability and convergence stability. Optimizer parameters, especially learning rate and weight decay, depend on the backbone structure of each branch and are set differently for image and point cloud branches. This difference in policy optimization ensures that the two branches are trained according to their specific network structure and data characteristics, resulting in better performance for the multimodal training task.
The reasoning process is shown in Figure 2. During inference, we can encode arbitrary open word categories into text queries and calculate their similarity to 3D point clouds. Specifically, we associate each point with the class with the highest calculated cosine similarity. Since we have distilled image-text alignment to point cloud-text alignment, there is no need to process images during inference.







Conclusion. This paper proposes a unified multimodal learning framework for open world 3D scene understanding, UniPLV, which does not need to make point cloud text pairs, and uses images as Bridges to propose logical distillation, feature distillation and vision-point cloud matching modules. In addition, we introduce four task-specific loss functions and a two-stage training process to achieve stable multimodal learning. Our approach significantly outperforms state-of-the-art methods on the nuScenes dataset. In addition, experimental results on different 3D backbones and on Waymo and Semantickitti datasets also demonstrate the scalability and lightweight character of our approach.
Future work. Some work needs to be improved and solved in the future. Our proposed framework has so far only been validated on outdoor datasets. In the future, we plan to extend validation to indoor datasets such as ScanNet, where the projection parameters between 2D and 3D are more accurate. We will refine and quantify the image branches in the future to enable the proposed framework to achieve both 2D and 3D open world scene understanding tasks. Point cloud branches can also be replaced with OCC occupancy prediction networks to expand open world applications.

2025-02-17

2025-02-14

2025-02-13


抖音二维码

微信公众号

QQ群:

小红书二维码
friend link


400-000-0000
立即获取方案或咨询
top







